To build data systems that are fair and useful, intersectionality must be woven into every stage of the data value chain, from planning and collection to analysis, sharing, and decision-making. Instead of treating identity as a checklist, intersectional policy development asks: Who participates in data collection? Whose voices are captured? How is data analysed and used? Does the final policy or product benefit everyone, especially those at the crossroads of different disadvantages?
What is the ‘Data Value Chain’?
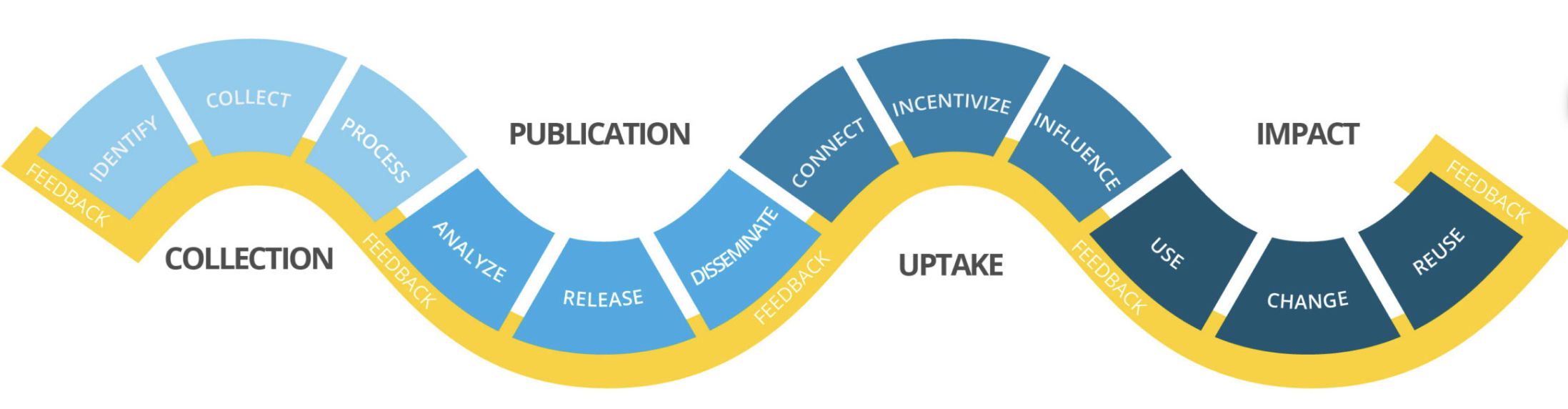
The Data Value Chain describes the evolution of data from collection to analysis, dissemination, and the final impact of data on decision making. In their model, data travels through four major stages: collection, publication, uptake, and impact. This journey relies on continuous feedback between data producers and stakeholders so the system can improve over time.
The Data Value Chain moves through four major stages:
- Collection: How data about people and communities is gathered
- Publication: How collected data is released and shared
- Uptake: How data gets used by policymakers, researchers, civil society, and communities
- Impact: How data informs decisions, changes policies, and improves lives
At each stage, intersectionality asks: Who participates? Whose voices are captured? Who benefits? Who might be harmed?
Five Stages of Establishing Intersectional Approaches to Data in Africa
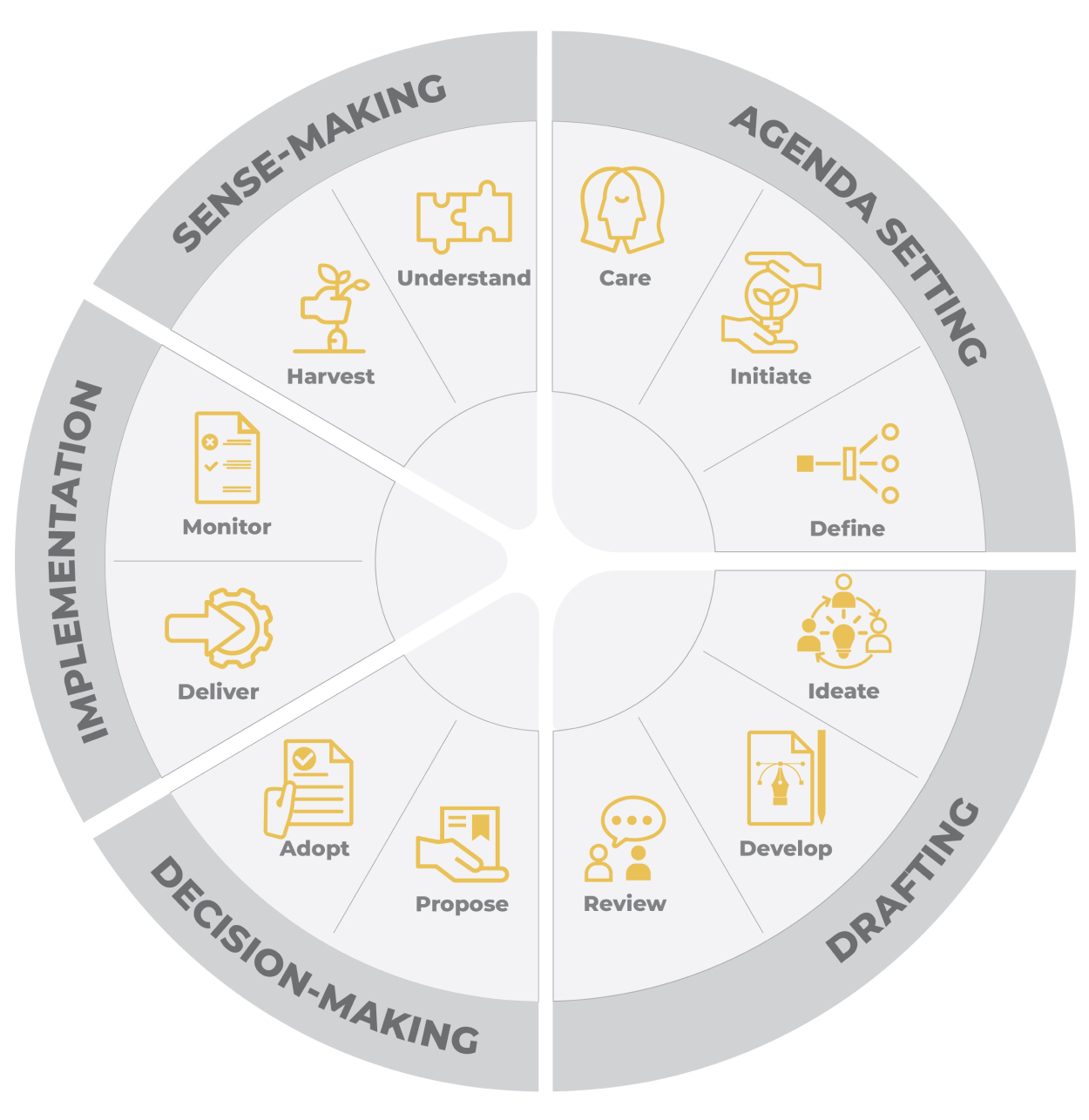
In addition to outlining the five stages of the data value chain, we will lightly apply i4Policy’s ADDIS Decision Thinking approach as a practical guide for how inclusive choices can be made within each stage of a policy cycle. ADDIS, a mnemonic for Agenda, Drafting, Decision-making, Implementation, and Sense-making, is an approach to decision thinking that brings together approaches from modern and traditional policy cycle frameworks with the iterative, non-linear and modular nature of design thinking. The ADDIS methodology is broken down into 5 phases, and 12 steps.
We use ADDIS here as a “mini-cycle” to highlight recurring governance questions that show up across the chain. These questions include, but are not limited to, what matters and for whom, who needs to be involved, what options exist and which trade-offs are acceptable, how decisions will be implemented responsibly, and what can be learned and improved in the next iteration. By focusing on how decisions are implemented responsibly and what can be learned and improved in the next iteration, this approach transforms abstract intersectional goals into action-oriented results.
The Five Stages of Establishing an Intersectional Approach
Listening to the Full Story
What is Data Collection?
Collection is how data about people and communities gets gathered in the first place. An intersectional approach means asking questions and designing surveys that let people express more than one part of who they are, like being a young, rural woman who’s differently abled, rather than just ticking a single box. This means working directly with local organisations and trusted networks to reach those who are usually missed, and making sure that categories reflect real-life complexity, not just what’s easy to measure.
What’s at stake
Who gets counted, how, and by whom sets the foundation for all downstream data use. In many African contexts, intersecting identities, like gender, age, disability, language, and migratory status, often shape who is visible in official data and who remains hidden.
Intersectional Data Collection through an ADDIS lens
Operationalising Data Collection during the Agenda-setting phase – Care, Initiate, Define. Before tools are finalised, apply a short participatory cycle:
Care is the step where one better understands the situation by empathising with the people and organisations affected. In other words, before you design a survey or registry, you take time to learn what people’s lived realities look like, how they experience exclusion, and where harm or invisibility might happen.
- You can carry out activities like Focus Group Discussions, community round-table meetings, key informant interviews (or other listening methods) to understand who is missing and why.
- It is also useful to consult with policy analysts as they can help prioritize disaggregation by key attributes important to national development.
Initiate is where we move from “we’ve heard the issues” to “we’ve set up the right group, values, and way of working to engage in this data collection process well.”
- The responsible institution can convene a small cross-sector working group (National Statistical Office, relevant ministry, CSOs, traditional leaders) and agree what “safe, inclusive data” means in this context.
Define is the step where institutions work together to identify and prioritise the specific issues to be addressed. It answers the questions, “What exactly are we trying to measure, for what decisions, and which intersections matter most in data collection?”
- Given that we can’t disaggregate everything all at once, choose which identity axes are most decision-relevant (e.g., sex + age + disability + location).
- Intersectional data gathered through administrative systems and alternative sources are particularly important.
Making Data Accessible and Meaningful
What is Data Publication?
Publication is how collected data gets released and shared. An intersectional approach to publication means releasing data in formats and languages that work for different communities, not just technical experts. It involves making disaggregated datasets available while protecting the privacy and dignity of individuals, especially those from marginalised groups.
What’s at stake
If data is published without proper disaggregation, it hides the experiences of marginalised groups. Poor publication practices — like releasing data only in English, or in formats inaccessible to CSOs — can perpetuate existing inequalities even when the underlying data is high quality.
Intersectional Data Publication through an ADDIS lens
Operationalising Data Publication during the Drafting phase – Develop, Ideate, Review:
Develop a publication plan that specifies how intersectional data will be released. Determine which metadata standards will be used, which disaggregations will be made available, and what access controls (open vs. restricted) are appropriate for sensitive intersectional data.
Ideate on formats and channels that will reach marginalised communities. Consider community data hubs, local language translations, visualisations that don’t require technical literacy, and partnerships with CSOs that can amplify reach to specific intersectional groups.
Review publication outputs with community representatives before final release. Check that data about marginalised groups is represented accurately and that the publication cannot be misused to discriminate or exclude.
Ensuring Data Reaches Those Who Need It
What is Data Uptake?
Uptake refers to how data gets used by policymakers, researchers, civil society, and communities themselves. An intersectional approach to uptake means not just making data available, but actively supporting different types of users — especially those representing marginalised groups — to find, understand, and act on data.
What’s at stake
Data that is collected and published but never used has no impact. Many communities most affected by inequality — rural women, people with disabilities, linguistic minorities — often lack the tools, resources, or access to make use of official data. Intersectional uptake strategies bridge this gap.
Intersectional Data Uptake through an ADDIS lens
Operationalising Data Uptake during the Decision-making phase – Progress, Adopt:
Progress toward uptake by building capacity among data users. Train CSO staff, local government officials, and community leaders to engage with intersectional data. Provide simplified data briefs and visualisations tailored to non-technical audiences, making it easier to use data for advocacy and decision-making.
Adopt participatory mechanisms that bring marginalised communities into data interpretation. Community data audits, participatory data analysis sessions, and co-creation of data stories ensure that the people most affected by data have agency in how it is understood and applied.
Measuring Change for Whom?
What is Data Impact?
Impact is the ultimate goal of the data value chain: data that informs decisions, changes policies, and improves lives. An intersectional approach to impact goes beyond measuring headline outcomes to asking whose lives changed, who was left out, and what unintended consequences emerged for different intersecting groups.
What’s at stake
Impact measured without an intersectional lens can declare success while leaving the most marginalised behind. If aggregate indicators improve but conditions for multiply-disadvantaged groups worsen, the system has failed. Intersectional impact measurement holds programmes accountable to equity, not just efficiency.
Intersectional Impact Measurement through an ADDIS lens
Operationalising Impact during the Implementation phase – Deliver, Monitor:
Deliver disaggregated impact assessments that track outcomes across intersecting identity markers. Design monitoring frameworks before implementation begins, specifying which intersecting groups will be tracked and how. Ensure frontline staff can report disaggregated outcomes in real-time.
Monitor not just reach, but equity of impact. If uptake is high but benefits are concentrated in already-advantaged groups, flag this as a system failure rather than a lack of demand. Establish community liaison roles who can surface experiences of exclusion that don’t appear in quantitative data.
Closing the Loop for Continuous Learning
What is Feedback in the Data Value Chain?
Feedback is the mechanism that makes the data value chain a living system rather than a one-way pipeline. Intersectional feedback means creating structured ways for the people who are counted, the communities whose data is used, and the data users to communicate back to data producers about gaps, errors, harms, and missed intersections.
What’s at stake
Without systematic feedback, every stage of the chain repeats the same gaps. Communities most harmed by data misrepresentation often have the least power to demand correction. Intersectional feedback systems flip this dynamic, building accountability into the data lifecycle by design.
Cross-Cutting Intersectional Principles
Several principles apply across all five stages of the chain:
- Nothing about us without us: Meaningful participation of marginalised communities at every stage, from design to evaluation.
- Data minimisation with dignity: Collect only what is needed, with the strongest protections for sensitive intersectional data.
- Disaggregation by design: Build disaggregation requirements into contracts, data standards, and system architectures from the start.
- Accountability chains: Identify who is responsible for intersectional data quality at each stage, with consequences for failures.
- Iterative learning: Treat every data cycle as a learning opportunity and create formal mechanisms to incorporate what is learned into future cycles.
Intersectional Feedback through an ADDIS lens
Operationalising Feedback during the Sense-making phase – Harvest, Understand:
Harvest feedback systematically from communities, data users, and frontline implementers. Use participatory methods — community scorecards, story circles, complaint mechanisms — that are accessible to people with different literacy levels, languages, and disabilities.
Understand what feedback signals about gaps in intersectionality across the chain. Analyse patterns in who is complaining, who is not being heard, and what categories of exclusion keep appearing. Feed this learning back into the agenda-setting stage of the next cycle, completing the loop.
How would you approach these scenarios?
How to Play
- For each scenario, imagine you’re a policymaker, regulator, or CSO.
- What intersectional barriers do you see?
- What 2–3 steps would you take to solve it?
The “Invisible” Entrepreneur
Fatoumata is a widowed woman, living in a rural border region. She runs a small informal market stall, speaks a local minority language, and doesn’t have a national ID.
The Challenge: The latest women’s financial inclusion program is only accessible online, requires an official address, and documentation in French or English.
Prompt: What could you do to make sure Fatoumata, and other women like her, aren’t left behind?
Your Response

The Data Gap
A national disability survey has just been published. The data shows that 12% of the population lives with some form of disability. But the dataset has no breakdown by gender, location, or type of disability.
The Challenge: The government is now using the aggregate 12% figure to design a single, one-size-fits-all disability support programme. A CSO working with deaf women in urban areas can’t find their community in the data at all.
Prompt: How would you advocate for better data disaggregation, and what intersections would you prioritise?
Your Response

The Youth Researcher
Amara is a 19-year-old researcher at a community organisation. She wants to use national education data to show how girls from pastoralist communities drop out of school at much higher rates than the national average suggests.
The Challenge: The open data portal requires a government email address to download the full dataset – something her small CSO doesn’t have. Even the data that is publicly available only breaks down by gender AND by region separately. There is no way to see what happens at the intersection of both.
Prompt: What changes to data publication and access policies would help Amara and researchers like her?
Your Response